AI & Enterprise
InsightFlow
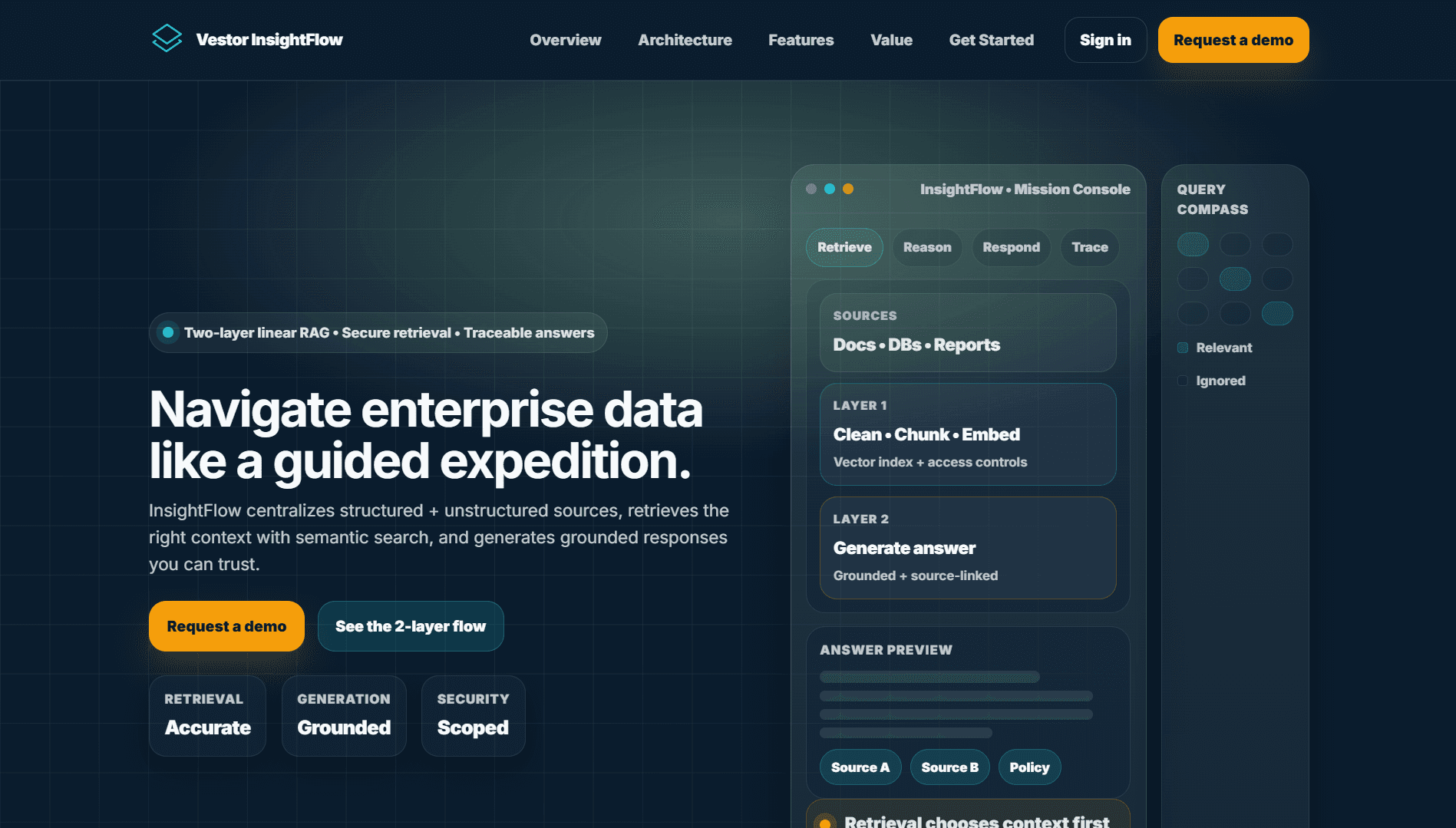
A secure, enterprise RAG platform that retrieves the right context from structured and unstructured data and generates source-traceable, grounded answers through a two-layer linear pipeline.
Tech Stack
Project Overview
About InsightFlow
InsightFlow
Tech stack used: Next.js, React, TypeScript, Tailwind CSS, Python, FastAPI, GraphQL, LangChain, OpenAI, Pinecone, PostgreSQL, MongoDB, Redis, AWS, Docker
Project description
InsightFlow is a RAG (Retrieval-Augmented Generation) platform that ingests documents and structured data and uses a two-layer retrieval pipeline to deliver source-traced, grounded answers suitable for compliance-focused enterprises.
Challenges we tackled and how we handled them
Context Retrieval Accuracy - Implemented a hybrid retrieval approach combining dense embeddings (Pinecone) with sparse matching (BM25) and a re-ranking layer to return the most relevant chunks for LLM input.
Answer Grounding and Citations - Ensured every generated answer includes inline citations and confidence scores so users can verify information against source passages.
Document Processing Pipeline - Built modular extractors for multiple formats (PDF, Word, HTML) with intelligent chunking that preserves semantic boundaries for better retrieval.
Enterprise Security Requirements - Enforced document-level access controls that propagate to search results and answer visibility to prevent data leakage.
Capabilities
Key Features
Natural language question answering
Source-cited responses with confidence scores
Multi-format document ingestion
Knowledge graph visualization
Conversation history and context
Admin dashboard for content management
API access for integrations
Usage analytics and query insights
Problem Solving
Challenges We Tackled
Every project presents unique challenges. Here's how we approached and solved the key technical hurdles.
Context Retrieval Accuracy
Finding the most relevant context from millions of documents is crucial for answer quality.
Hybrid search combining dense embeddings (Pinecone) with sparse keyword matching (BM25). Re-ranking layer scores retrieved chunks for relevance before LLM processing.
Answer Grounding and Citations
Users need to verify AI-generated answers against original sources for trust and compliance.
Each generated answer includes inline citations linking to exact source passages. Confidence scores indicate how well the answer is supported by retrieved context.
Document Processing Pipeline
Ingesting diverse document formats (PDF, Word, HTML, databases) with varying structures.
Modular document processing pipeline with format-specific extractors. Intelligent chunking preserves semantic boundaries while maintaining optimal chunk sizes for retrieval.
Enterprise Security Requirements
Sensitive documents require strict access controls even in search results.
Document-level access controls propagate to search results. Users only see answers derived from documents they're authorized to access.
Technology
Built With Modern Stack
Interested in a similar solution?
We build custom software solutions tailored to your business needs. Let's discuss how we can help you achieve your goals.